
Olá! Neste post, você vai aprender sobre a linguagem SQL- que é uma das mais importantes da programação.
Mas por que o SQL é tão importante? Bem, quando trabalhamos com bancos de dados, é fundamental termos uma maneira de acessar e manipular os dados contidos neles. E é aí que entra o SQL, uma linguagem padrão utilizada em praticamente todos os sistemas de gerenciamento de banco de dados.
Sendo assim, o objetivo deste post é apresentar os conceitos básicos da linguagem SQL, desde sua estrutura até os comandos mais utilizados. Se você precisa criar seu primeiro banco de dados e não sabe por onde começar, esse é o post certo.
A partir de agora, você vai entender os conceitos do SQL. Acompanhe cada tópico para entender como essa linguagem é essencial para trabalhar com bancos de dados.
Importância do SQL
O SQL é uma linguagem padrão que permite acessar e manipular bancos de dados de forma eficiente e organizada. A linguagem SQL está presente em diversos sistemas de gerenciamento de banco de dados e é uma das principais linguagens para a consulta e manipulação de dados.
Logo, a importância do SQL se dá pelo fato de que ele permite que possamos acessar e manipular informações em bancos de dados de forma rápida e fácil. Por meio de comandos específicos, conseguimos realizar consultas, inserções, atualizações e exclusões de dados em poucos segundos.
Além disso, o SQL permite que as informações contidas em um banco de dados se organizem de maneira lógica e estruturada. É possível criar tabelas, relacionar informações entre elas, estabelecer regras de integridade e criar índices para otimizar o desempenho das consultas.
O que é SQL?
SQL, ou Structured Query Language, é uma linguagem de programação utilizada para gerenciar bancos de dados relacionais. Foi criada na década de 1970 por Donald D. Chamberlin e Raymond F. Boyce, enquanto trabalhavam na IBM. Desde então, a linguagem tornou- se um padrão para gerenciamento de bancos de dados, sendo muito popular ao redor do mundo.
Definição e história da linguagem
- A definição de SQL é simples: é uma linguagem de consulta que permite acessar e manipular informações em bancos de dados.
Isso significa que o SQL é uma linguagem de alto nível que simplifica a interação com bancos de dados, permitindo que usuários e desenvolvedores realizem consultas, inserções, atualizações e exclusões de dados de maneira rápida e organizada.
Em suma, a história do SQL começa na década de 1970, quando a IBM estava desenvolvendo um sistema de gerenciamento de banco de dados relacional chamado System R. Nesse contexto, Donald D. Chamberlin e Raymond F. Boyce, contratados para criar uma linguagem de consulta para o sistema, desenvolveram a que seria conhecida como SQL.
Ao longo dos anos, o SQL evoluiu e se tornou um padrão para gerenciamento de bancos de dados relacionais. Em 1986, o SQL foi padronizado pela primeira vez pela ANSI (American National Standards Institute) e, em 1987, pela ISO (International Organization for Standardization).
Atualmente, utiliza-se o SQL em diversos sistemas de gerenciamento de bancos de dados, como MySQL, Oracle, Microsoft SQL Server, PostgreSQL e SQLite.
Portanto, dominar essa linguagem é fundamental para quem pretende trabalhar com bancos de dados e desenvolvimento de software, sendo uma das principais habilidades exigidas no mercado de trabalho.
Funcionamento básico da linguagem SQL
Seu funcionamento é bastante simples: a linguagem permite acessar e manipular informações de forma organizada. Isto é possível por meio de comandos específicos ao banco de dados.
Desta forma, os comandos SQL realizam diversas operações, como:
- criar tabelas
- inserir dados
- atualizar registros
- excluir informações
- realizar consultas
Sendo assim, escrevem-se esses comandos em um editor de texto e os enviam ao banco de dados.
Com isso, ao enviar um comando, o sistema executa a operação. Por exemplo, se for uma consulta, o banco de dados irá buscar os dados solicitados e retornar o resultado.
Outro aspecto importante do funcionamento do SQL é a sua capacidade de relacionar informações entre diferentes tabelas em um banco de dados.
Isso é possível por meio das chaves primárias e estrangeiras, pois elas conectam as tabelas e permitem a consulta e a manipulação dos dados.
Além disso, o SQL possui diversas funções e operadores que realizam cálculos, filtros e outras manipulações nos dados. Isso torna a linguagem extremamente poderosa e versátil, permitindo que os usuários possam extrair insights valiosos e tomar decisões baseadas em dados.
Diferença entre DDL, DML e DQL
Primeiramente, o SQL divide-se em três principais subconjuntos: DDL, DML e DQL. Cada um desses subconjuntos possui um conjunto diferente de comandos e funcionalidades. Abaixo, vou explicar a diferença entre eles.
- DDL (Data Definition Language): define a estrutura do banco de dados. Os comandos DDL criam, modificam e excluem objetos do banco de dados, como tabelas, índices, chaves primárias e estrangeiras, entre outros. Alguns exemplos de comandos DDL são CREATE, ALTER e DROP.
- DML (Data Manipulation Language): manipula os dados do banco de dados. Os comandos DML inserem, atualizam e excluem dados de tabelas. Alguns exemplos de comandos DML são INSERT, UPDATE e DELETE.
- DQL (Data Query Language): realiza consultas no banco de dados. Os comandos DQL selecionam dados de tabelas, realizam cálculos e agrupam de dados. O comando mais utilizado em DQL é o SELECT.
É importante ressaltar que, apesar de cada subconjunto possuir comandos específicos, a gente pode usá-los de forma integrada para realizar diversas operações em um banco de dados. Por exemplo, é possível criar uma tabela (DDL), inserir dados nela (DML) e depois realizar consultas para buscar informações específicas (DQL).
Criando tabelas com SQL
Definição e características de tabelas
Uma tabela é a estrutura fundamental de um banco de dados, onde as informações armazenam-se de forma organizada. Cada tabela possui linhas (também conhecidas como registros) e colunas (também conhecidas como campos).
Além disso, as tabelas podem ter restrições que ajudam a garantir a integridade dos dados e a manter a consistência do banco de dados. As restrições definem regras para as informações inseridas na tabela, enquanto as chaves primárias garantem que cada registro na tabela seja único e identificável.
Outra característica importante das tabelas é a capacidade de relacionar informações entre diferentes tabelas em um banco de dados.
E isto é feito por meio das chaves estrangeiras, que estabelecem conexões entre as tabelas, permitindo que consultemos e manipulemos os dados.
Comandos SQL para criar tabelas
Para criar uma tabela em SQL, é necessário utilizar o comando CREATE TABLE, seguido pelo nome da tabela e pelas definições de suas colunas. Cada coluna deve ter um tipo de dado específico. Veja abaixo, um exemplo para criar uma tabela simples:
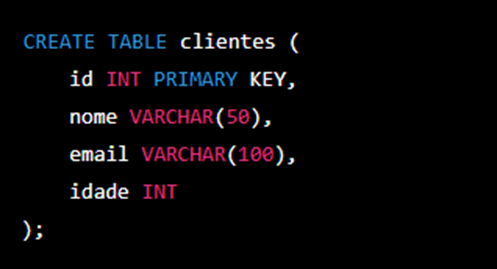
No exemplo acima, a tabela “clientes” é criada com quatro colunas: “id”, “nome”, “email” e “idade”. A coluna “id” é a chave primária da tabela, garantindo que cada registro seja único e identificável. As outras colunas são VARCHAR (para strings) e INT (para números inteiros).
Além disso, é possível adicionar restrições e chaves estrangeiras à tabela utilizando outros comandos SQL. Por exemplo, o comando ALTER TABLE adiciona novas colunas ou altera as existentes, enquanto o comando DROP TABLE exclui a tabela e seus registros do banco de dados.
É importante lembrar que cada banco de dados tem suas particularidades e variações na sintaxe dos comandos SQL, portanto é recomendável consultar a documentação específica de cada um.
Inserindo e manipulando dados com SQL
Como inserir dados em tabelas
Para inserir dados em uma tabela, basta utilizar o comando INSERT INTO, seguido pelo nome da tabela e pelos valores em cada coluna. Veja abaixo, um exemplo para inserir um registro na tabela “clientes”:

Neste exemplo, o comando INSERT INTO adiciona um registro na tabela “clientes”. Os valores inseridos correspondem a cada coluna da tabela, sendo o “id” igual a 1, o “nome” igual a “João Silva”, o “email” igual a “joao.silva@email.com” e a “idade” igual a 30.
Além do comando INSERT INTO, há outros comandos SQL para manipular os dados em uma tabela. O comando SELECT consulta os dados de uma tabela, o comando UPDATE atualiza e o comando DELETE exclui os registros. Mas não se preocupe, vamos ver mais sobre eles adiante.
Como atualizar e excluir dados em tabelas
Para atualizar dados em uma tabela em SQL, basta usar o comando UPDATE, seguido pelo nome da tabela e pelas informações que vamos atualizar. Abaixo, mostro um exemplo de comando SQL para atualizar o registro com o “id” igual a 1 na tabela “clientes”:
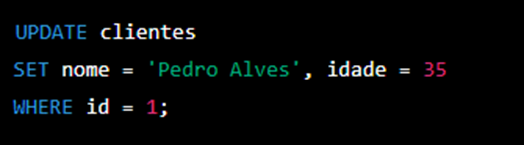
No exemplo acima, o comando UPDATE atualiza o registro com o “id” igual a 1 na tabela “clientes”. A cláusula SET define as informações que serão atualizadas, sendo o “nome” alterado para “Pedro Alves” e a “idade” alterada para 35. A cláusula WHERE define qual registro será atualizado, sendo o registro com o “id” igual a 1.
Para excluir dados em uma tabela em SQL, é só usar o comando DELETE, seguido pelo nome da tabela e pela condição que define quais registros serão excluídos. Veja só um exemplo de comando SQL para excluir todos os registros da tabela “clientes” com a “idade” menor que 18:
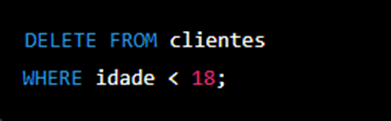
Veja que o comando DELETE exclui todos os registros da tabela “clientes” com a “idade” menor que 18. A cláusula FROM define de qual tabela serão excluídos os registros. A cláusula WHERE define a condição que deve ser atendida pelos registros que serão excluídos, sendo a “idade” menor que 18.
Consultando dados com SQL
Como fazer consultas em tabelas
Para consultar dados em uma tabela em SQL, basta usar o comando SELECT, seguido pelos campos que vão retornar na consulta e pelo nome da tabela que você vai consultar. Abaixo, mostro um exemplo de comando SQL para consultar todos os registros da tabela “clientes”:

Neste exemplo, o comando SELECT retorna todos os campos da tabela “clientes”. O “*” indica que todos os campos devem retornar na consulta.
É possível também selecionar apenas alguns campos específicos da tabela. Veja só um exemplo de comando SQL para consultar apenas o “nome” e a “idade” dos registros da tabela “clientes”:

No exemplo acima, o comando SELECT retorna apenas os campos “nome” e “idade” da tabela “clientes”.
Além disso, a gente pode utilizar a cláusula WHERE para definir condições que devem ser atendidas pelos registros que serão retornados na consulta. Veja abaixo um exemplo para consultar apenas os registros da tabela “clientes” com a “idade” igual a 18:
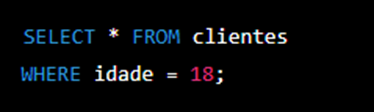
Neste exemplo, o comando SELECT retorna todos os campos da tabela “clientes” onde a “idade” é igual a 18.
Uso de operadores e funções em consultas SQL
Os operadores e funções em consultas SQL auxiliam na filtragem e manipulação de dados em tabelas. Veja só alguns exemplos de operadores e funções mais utilizados em consultas SQL.
Operadores de comparação:
- Igual (=)
- Diferente (<> ou !=)
- Maior que (>)
- Menor que (<)
- Maior ou igual que (>=)
- Menor ou igual que (<=)
Exemplo de uso de operadores em consultas SQL:

Funções de agregação:
- COUNT: retorna o número de registros
- SUM: retorna a soma de valores em um campo
- AVG: retorna a média de valores em um campo
- MAX: retorna o maior valor em um campo
- MIN: retorna o menor valor em um campo
Exemplo de uso de funções em consultas SQL:

Funções de manipulação de texto:
- CONCAT: concatena dois ou mais campos de texto
- UPPER: converte o texto para maiúsculo
- LOWER: converte o texto para minúsculo
- LEFT: retorna os primeiros caracteres do texto
- RIGHT: retorna os últimos caracteres do texto
- LENGTH: retorna o comprimento do texto
Exemplo de uso de funções de manipulação de texto em consultas SQL:

Ordenando e agrupando dados com SQL
Como ordenar dados
Em consultas SQL, a gente pode ordenar os resultados obtidos de acordo com um ou mais campos específicos. Para ordenar os resultados, utilizamos o comando ORDER BY, seguido do nome do campo pelo qual desejamos ordenar. Podemos escolher se a ordenação será crescente (ASC) ou decrescente (DESC).
Veja só:
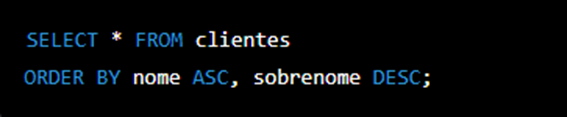
Neste exemplo, os resultados da consulta ordenam-se pelo campo “nome” em ordem crescente, e em caso de empate, pelo campo “sobrenome” em ordem decrescente.
Além disso, a gente pode agrupar os resultados de acordo com um determinado campo, utilizando o comando GROUP BY. Isso permite que possamos realizar funções de agregação, como vimos acima, em grupos específicos de dados.
Veja mais esse exemplo:

Dessa forma, a consulta retorna o número de clientes para cada cidade presente na tabela “clientes”. O resultado é agrupado pelo campo “cidade” utilizando o comando GROUP BY. Já a função COUNT(*) faz a contagem do número de registros em cada grupo.
Portanto, conhecer os comandos de ordenação e agrupamento de dados com SQL é importante para que possamos obter resultados mais precisos e organizados em nossas consultas.
Como agrupar dados na linguagem SQL
Para agrupar os resultados de uma consulta SQL, utilizamos o comando GROUP BY, seguido do nome do campo pelo qual queremos agrupar os resultados.
Por exemplo, suponha que temos uma tabela de vendas com as colunas “produto”, “data”, “quantidade” e “preço”. Para obter o total de vendas por produto, podemos utilizar o seguinte comando SQL:
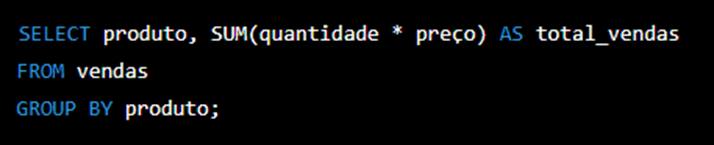
Neste exemplo, utilizamos a função SUM para calcular o total de vendas de cada produto, e agrupamos os resultados pelo campo “produto” utilizando o comando GROUP BY.
Também é possível agrupar por mais de um campo. Por exemplo, para obter o total de vendas por produto e por ano, podemos utilizar o seguinte comando SQL:

Neste exemplo, utilizamos a função YEAR para obter o ano da data de cada venda, e agrupamos os resultados pelos campos “produto” e “ano”.
Unindo tabelas com SQL
Conceito de junção de tabelas em SQL
Em SQL, a junção de tabelas combina dados de duas ou mais tabelas relacionadas. Essa operação é útil quando precisamos recuperar informações armazenadas em tabelas diferentes e que precisam ser mescladas para gerar um resultado completo.
Para realizar uma junção de tabelas em SQL, utilizamos o comando JOIN, seguido do nome da tabela que desejamos unir e da condição de junção. Existem vários tipos de junções em SQL, sendo as mais comuns a INNER JOIN e a OUTER JOIN.
A INNER JOIN retorna apenas os registros que possuem correspondência nas duas tabelas envolvidas na junção. A condição de junção é especificada através do uso da cláusula ON, que define a igualdade entre as colunas das duas tabelas que unirão os registros.
Já a OUTER JOIN é retorna todos os registros de uma tabela e os registros correspondentes na outra tabela. Existem três tipos de OUTER JOIN: LEFT JOIN, RIGHT JOIN e FULL OUTER JOIN, cada um retornando resultados diferentes.
Em resumo, a junção de tabelas em SQL é uma operação essencial para combinar dados de tabelas diferentes e obter informações mais completas e úteis para análise e tomada de decisão.
Tipos de junções em SQL
Como disse acima, em SQL, existem vários tipos de junções que podemos utilizar para combinar dados de tabelas relacionadas. Abaixo, apresento os quatro tipos mais comuns de junções:
INNER JOIN
A INNER JOIN é a junção mais simples e comum em SQL. Ela retorna apenas os registros que possuem correspondência nas duas tabelas envolvidas na junção. A condição de junção é especificada através do uso da cláusula ON, que define a igualdade entre as colunas das duas tabelas que serão utilizadas para unir os registros.
Exemplo:
Suponha que você tenha duas tabelas, uma chamada “clientes” e outra chamada “pedidos”. A tabela “clientes” possui os seguintes campos: “id_cliente”, “nome” e “email”. Já a tabela “pedidos” possui os campos “id_pedido”, “id_cliente” (chave estrangeira que faz referência ao id do cliente que fez o pedido) e “valor_total”.
Para realizar uma junção INNER JOIN entre essas duas tabelas, você usaria o seguinte comando SQL:

Nesse exemplo, a cláusula INNER JOIN junta as informações da tabela “clientes” com a tabela “pedidos”. O comando SELECT seleciona as colunas que serão exibidas no resultado final da consulta.
O ON especifica a condição de junção entre as tabelas, comparando o campo “id_cliente” da tabela “clientes” com o campo “id_cliente” da tabela “pedidos”. Dessa forma, o resultado da consulta irá mostrar o nome do cliente, o id do pedido e o valor total do pedido para cada registro que atenda a essa condição de junção.
LEFT JOIN
O LEFT JOIN retorna todos os registros da tabela à esquerda da cláusula JOIN, juntamente com os registros correspondentes na tabela à direita. Caso não haja correspondência entre os registros, o resultado da tabela à direita será nulo. O LEFT JOIN é útil quando precisamos obter todos os registros de uma tabela, mesmo que não existam correspondências na outra tabela.
Vamos tomar como exemplo, uma tabela chamada “produtos” e outra chamada “pedidos”. A tabela “produtos” possui os campos “id_produto”, “nome” e “preco”. Já a tabela “pedidos” possui os campos “id_pedido”, “id_produto” (chave estrangeira que faz referência ao id do produto que foi pedido), “quantidade” e “valor_total”.
Exemplo:
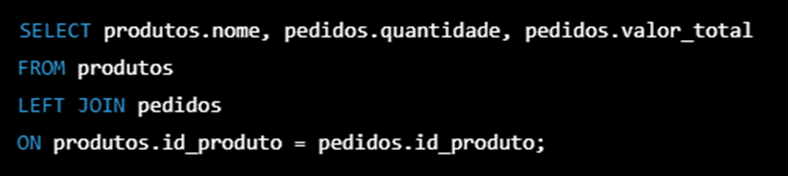
Nesse exemplo, a cláusula LEFT JOIN junta as informações da tabela “produtos” com a tabela “pedidos”, mas também para trazer os registros da tabela “produtos” que não possuem correspondência na tabela “pedidos”. Isso é útil para saber quais produtos ainda não foram vendidos.
O comando SELECT seleciona as colunas que serão exibidas no resultado final da consulta. O ON especifica a condição de junção entre as tabelas, comparando o campo “id_produto” da tabela “produtos” com o campo “id_produto” da tabela “pedidos”.
Sendo assim, o resultado da consulta irá mostrar o nome do produto, a quantidade de pedidos que foram feitos e o valor total. Caso um produto ainda não tenha sido pedido, ele será exibido no resultado da consulta com os campos referentes aos pedidos (quantidade e valor total) preenchidos com valores nulos.
RIGHT JOIN
O RIGHT JOIN é semelhante ao LEFT JOIN, porém retorna todos os registros da tabela à direita da cláusula JOIN, juntamente com os registros correspondentes na tabela à esquerda. Caso não haja correspondência entre os registros, o resultado da tabela à esquerda será nulo.
Vamos supor que temos duas tabelas em nosso banco de dados: “clientes” e “compras”. A tabela “clientes” contém informações sobre os clientes de uma loja, enquanto a tabela “compras” contém informações sobre as compras realizadas pelos clientes.
Ambas as tabelas têm uma coluna em comum, que é o “id_cliente”. Vamos fazer uma junção RIGHT JOIN para listar todos os clientes que fizeram compras e suas respectivas compras, mesmo que alguns clientes não tenham comprado nada.

Neste exemplo, estamos selecionando as colunas “nome” da tabela “clientes” e “produto” da tabela “compras”. A junção é feita usando o RIGHT JOIN. Em seguida, especificamos as duas tabelas que estamos unindo, “clientes” e “compras”, seguidas pela condição de junção “ON clientes.id_cliente = compras.id_cliente”. Isso significa que estamos unindo as tabelas com base no valor da coluna “id_cliente” presente em ambas.
O resultado da consulta será uma lista de todos os clientes que fizeram compras, incluindo aqueles clientes que não fizeram compras ainda, e os produtos que compraram.
FULL OUTER JOIN
O FULL OUTER JOIN retorna todos os registros das duas tabelas envolvidas na junção, juntamente com os registros correspondentes. Caso não haja correspondência entre os registros, os resultados das tabelas que não possuem correspondência serão nulos.
O FULL OUTER JOIN é útil quando precisamos obter todos os registros das duas tabelas, mesmo que não haja correspondências entre elas.
Vamos supor que temos duas tabelas: uma tabela de vendas e uma tabela de estoque. Queremos obter uma lista completa de todas as vendas e todas as informações de estoque correspondentes, mesmo que não haja correspondência em ambas as tabelas. Para isso, usaremos o comando FULL OUTER JOIN.
Tabela “vendas”:
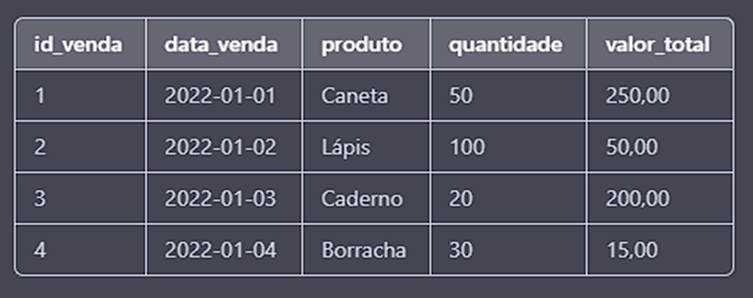
Tabela “estoque”:
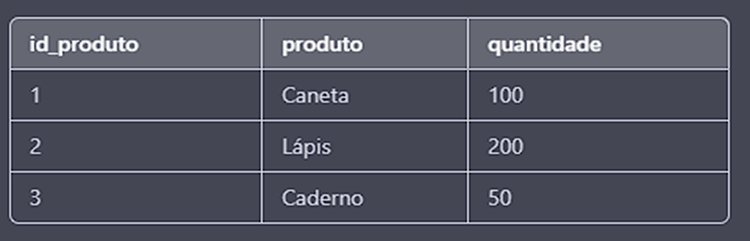
Para realizar a junção com o FULL OUTER JOIN, utilizamos o seguinte comando:
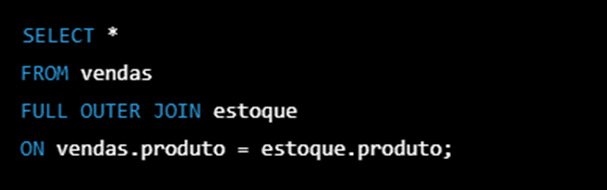
O resultado da consulta será:
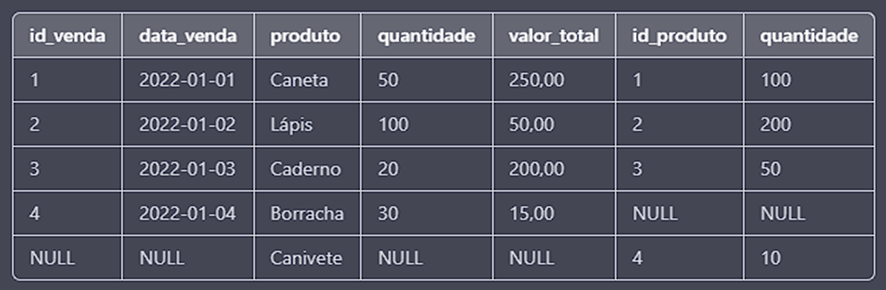
Observe que o resultado inclui todas as vendas, independentemente de haver correspondência ou não na tabela de estoque. Além disso, ele inclui todos os produtos da tabela de estoque, mesmo que não tenham sido vendidos. Os valores nulos representam ausência de correspondência.
Em resumo, os diferentes tipos de junções em SQL nos permitem combinar dados de tabelas relacionadas de diferentes maneiras, de acordo com nossas necessidades específicas. É importante entender as diferenças entre os tipos de junções para utilizá-los de forma eficiente e correta.
Conclusão
Neste post, você viu uma introdução à linguagem SQL, em que foi destacada sua importância como linguagem de consulta para bancos de dados.
Assim como você também descobriu o funcionamento básico do SQL, percebendo as diferenças entre DDL, DML e DQL.
Também aprendeu sobre os comandos SQL para criar tabelas, inserir e manipular dados, bem como realizar consultas utilizando operadores e funções.
Além disso, destacamos a importância de ordenar e agrupar dados com SQL, apresentando os comandos para realizar estas operações. Finalmente, falamos sobre junção de tabelas em SQL, explicando os diferentes tipos de junções disponíveis e apresentando um exemplo prático.
Em resumo, neste post, apresentei os principais conceitos e comandos da linguagem SQL, que são fundamentais para você que precisa aprender mais sobre banco de dados.
Espero que este conteúdo tenha sido útil e possa contribuir para os seus estudos em programação.
Sugestão de outras leituras para você se aprofundar na linguagem SQL:
- Introdução à Linguagem SQL: Abordagem prática para iniciantes, por Thomas Nield
- SQL – Guia Prático: um Guia Para o uso de SQL, por Alice Zhao.
- Aprendendo SQL: Dominando os Fundamentos de SQL, por Alan Beaulieu
- Use a Cabeça! SQL, por Lynn Beighley
- SQL Cookbook: Receitas de SQL para seu dia a dia, por Anthony Molinaro
AUTORA
Nayara Bonim
UI/UX Designer | UX Writer | Instructional Designer
Formada em Análise e Desenvolvimento de Sistemas (IFRO), Pós-Graduada em Engenharia de Software, MBA em Design Digital e Branding.
Last modified: 26 de julho de 2024





